The 60-second version
TRIBE v2 is the TRImodal Brain Encoder from Jean-Remi King's Brain and AI team at Meta FAIR Paris. It takes a video with synced audio and text, passes the content through frozen vision, audio, and language encoders, and outputs predicted fMRI BOLD response across roughly 70,000 cortical voxels. Announced in March 2026, trained on over 1,000 hours of fMRI from approximately 720 subjects, code on GitHub under facebookresearch/tribev2.
In one line: in-silico fMRI at the speed of inference. What used to require a scanner, a subject pool, and a study protocol now runs as a forward pass on a server.
Open-source brain encoding models at this quality level collapse the cost structure of behavioral prediction. The remaining moat is signal integration, not neural data alone.
How it works, minus the math
Input: a video clip, typically thirty seconds to a few minutes, with its audio track and an optional transcript.
Feature extraction runs in parallel across three frozen foundation models: DINOv2 for visual frames, wav2vec 2.0 for audio, and Llama-family embeddings for language. Each produces per-segment feature vectors.
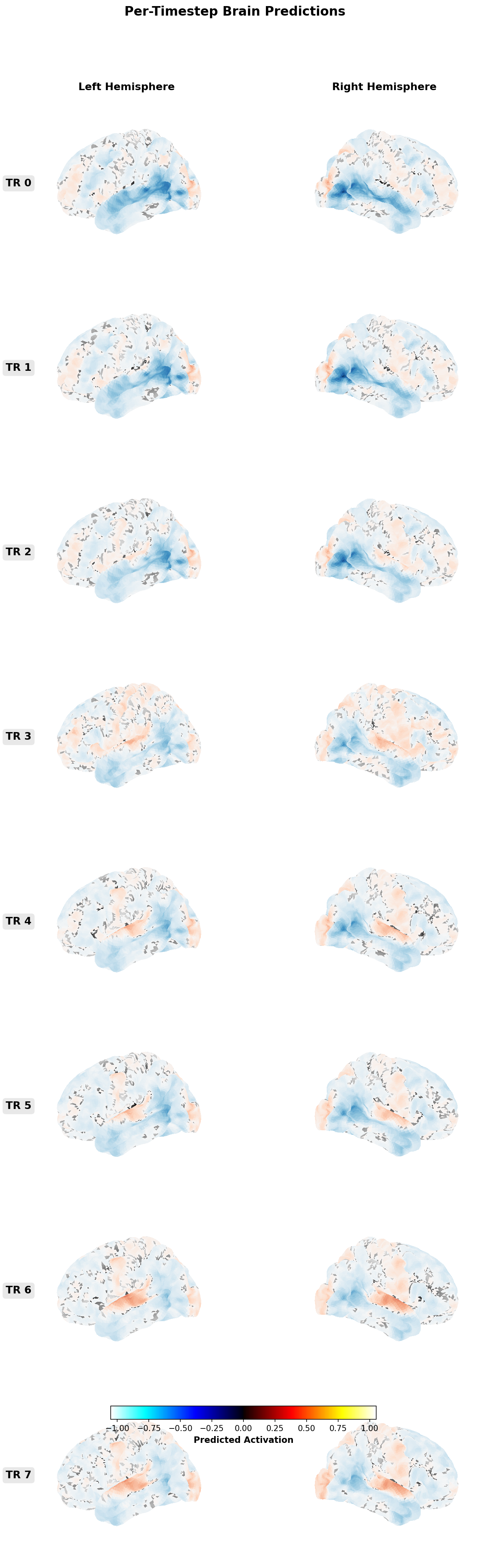
A transformer fusion stack learns to combine those features across a long temporal receptive field (minutes, not seconds) and project into a shared latent representation. Subject-specific readout heads map the shared latent to predicted BOLD response at the voxel level.
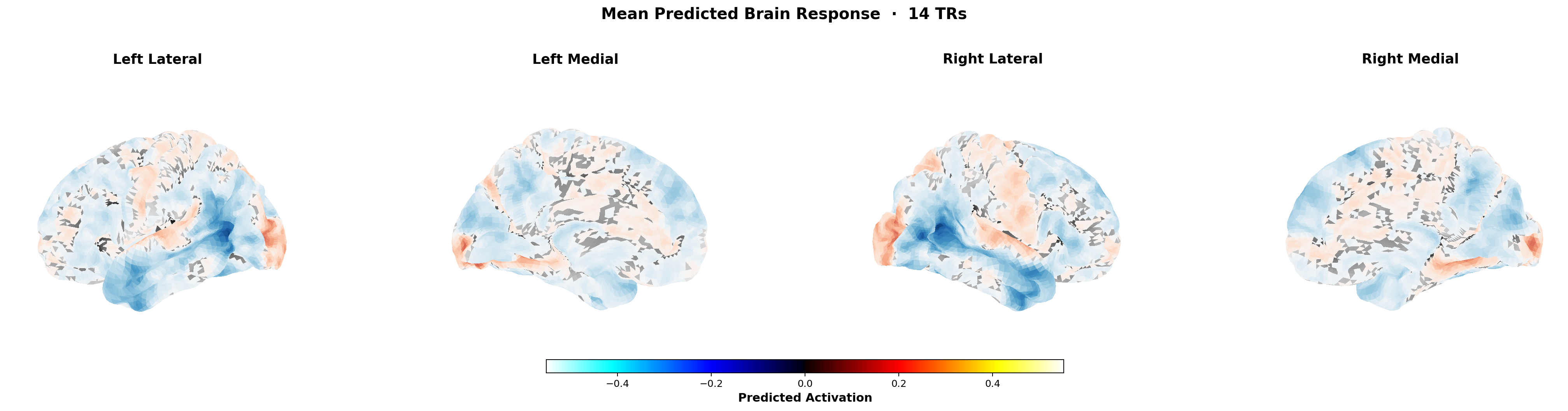
Output: predicted cortical activation per voxel per time step for a typical viewer. Aggregate across the training population, or apply a subject-specific readout learned from calibration data.
Why Algonauts 2025 matters
TRIBE v1 was the winning entry in the Algonauts Project 2025 challenge[1]. Algonauts is the standardized benchmark for encoding models: voxel-wise correlation on held-out CNeuroMod Friends subjects (roughly 80 hours of 7T fMRI per subject, organized by Gemma Roig, Radoslaw Cichy, and Aude Oliva at MIT CSAIL and Frankfurt).
Winning Algonauts is not the same as being commercially useful. It is evidence that the architecture generalizes across subjects on a held-out benchmark. That is necessary, not sufficient. The commercial test is calibration against real-world outcomes, which sits separately (see the calibration page).
v1 vs v2
- Longer temporal context. v1 operated on short clips. v2 fuses minutes of context before predicting.
- Shared latent with per-subject readouts. v1 was largely subject-specific. v2 trains a shared representation and adapts per subject with lightweight readout heads.
- Voxel resolution. v2 reports prediction across roughly 70,000 voxels, a 70x jump over v1.
- Zero-shot to held-out subjects. v2 generalizes to subjects not seen during training, at a meaningful (if degraded) accuracy. This is the headline capability for commercial use.
- Training corpus. v1 used the CNeuroMod Friends dataset. v2 expands to over 1,000 hours of fMRI across approximately 720 subjects drawn from Natural Scenes Dataset, Algonauts 2023, and movie-watching paradigms.
What TRIBE v2 is not
Not a decoder. TRIBE predicts brain response from stimulus. MindEye and MindEye2[2] do the reverse: reconstruct images from brain response. Both are useful; they solve different problems.
Not a neuromarketing vendor product. TRIBE is a model, not a service. Commercial vendors will wrap encoders like TRIBE into products, add calibration, and sell subscriptions. That is downstream of the release itself (see what is neuromarketing in 2026).
Not individual-level prediction. TRIBE predicts the typical-responder cortical trajectory for a given video. Individual prediction requires per-subject calibration data. Aggregate population prediction is where the method's strength lies.
How a marketing team would actually use it
Three concrete workflows that are useful today.
1. Pre-publication signal on ads. Run a TRIBE-derived score over every ad in your review stack. Use it as one of four signals (see the four signals framework). The neural signal will flag attentional weakness in the first three seconds that self-report screens will miss.
2. A/B design input before production. Score three cut options from different storyboards. Use the shape of the predicted response to pick which to fund. Not to make the decision unilaterally, but to reduce the ambiguity going into production.
3. Cross-cultural extrapolation. Zero-shot language transfer means you can score the same creative across languages without running a new study in each market. The confidence interval is wider; the directional read is usable.
The reverse-inference problem, sidestepped
Russell Poldrack's 2006 reverse-inference critique[3] has dogged legacy neuromarketing for twenty years. The critique: you cannot infer a cognitive process from a regional activation, because most regions activate under many conditions.
TRIBE does not make reverse inferences. It goes the other direction: stimulus in, predicted cortical response out. The claims it supports are predictive ("this creative will elicit this BOLD trajectory in a typical viewer"), not interpretive ("this activation means the viewer felt X"). Forward prediction frames route around the critique by construction.
We wrote a longer methodology piece on this (see the twenty-years-on piece).
Limits and honest caveats
- Training data is fMRI of people watching Friends. The dataset is wider than that now but still skewed toward long-form English video.
- Novel cultural content is out of distribution. Fresh meme formats, new platform-specific conventions, and non-Western video need validation before trusting the score.
- Short-form vertical video. TikTok-style creative is different enough from the training distribution to warrant calibration before use.
- Advertising-specific stimuli are underrepresented in the training corpus. The model generalizes, but the error bars widen.
- Field outcomes. Predicting BOLD is not predicting sales. Calibration against real performance is the next step, and we publish ours (see the calibration study).
- License. Research-only in its current release, matching prior Meta releases like Brain2Qwerty. Commercial use requires a separate pathway.
What this means for the category
Open-source forward encoding at this quality level makes the expensive substrate (scanner time, subject recruitment, study protocol) cheap. The commercial moat stops being "we have brain data." It becomes "we integrate brain data with linguistic, cultural, and historical signal and publish calibration." The infrastructure layer wins. Single-signal vendors lose.
For the founding argument (see the manifesto) and the framework (see the four signals).
References
- 1Algonauts Project 2025 challenge.
- 2Scotti et al. MindEye and MindEye2.
- 3Poldrack. Can cognitive processes be inferred from neuroimaging data? TICS 2006.
- 4Meta AI. TRIBE v2 release blog post.
- 5TRIBE arXiv preprint.
- 6Meta TRIBE v2 GitHub.
- 7CNeuroMod dataset.
- 8Defossez et al. Decoding speech perception from non-invasive brain recordings. Nature Machine Intelligence 2023.
- 9Caucheteux, Gramfort, King. Evidence of a predictive coding hierarchy in the human brain listening to speech. Nature Human Behaviour 2023.
- 10Jean-Remi King lab page.
- 11Tang, LeBel, Jain, Huth. Semantic reconstruction from non-invasive brain recordings. Nature Neuroscience 2023.
- 12Falk, Berkman, Lieberman. From neural responses to population behavior. Psychological Science 2012.