Why one signal is never enough
A content scoring system tells you whether a piece of content is ready to publish. The useful question is not "does it have a good score" but "what does the score actually measure." Every scoring product sold in 2026 is optimizing one signal family and calling the answer prediction. The Clearscope score is about SERP matching. The System1 score is about emotional response. The VidMob score is about attribute correlation. Each one works in its own lane. None holds up under distribution shift.
A piece of content that tests well in every single-signal tool can still flop. The failure mode is always the same: the tool did not measure what turned out to matter on the day the content ran.
Any predictive score that cannot be explained in terms of at least two independent signal families is a single-signal product with marketing copy on top.
The four signal families
Predictive content scoring in 2026 should combine four signal families. We wrote the canonical frame for these separately (see the four signals framework). Here is the pre-publication scoring view of each.
Neural. Predicted cortical response to the content via forward encoding models (TRIBE v2[1], MindEye). What a typical brain does in the first three seconds. Salience. Attention reliability across subjects.
Linguistic and affective. Psycholinguistic features of the text and audio. Emotional arc[2], arousal-valence mapping, persuasion-marker density, concreteness. LIWC[3] and VADER at the dictionary layer; LLM embeddings at the semantic layer.
Cultural. Distance from the current reference set and relevance to live conversation. Google Trends proximity, platform-specific currency, memetic salience. This is the signal that tells you an otherwise well-made ad is about to feel stale.
Historical. Performance of structurally similar creative in comparable contexts. Ad library archives, creative intelligence taxonomies, paid social benchmarks conditioned on audience and objective.
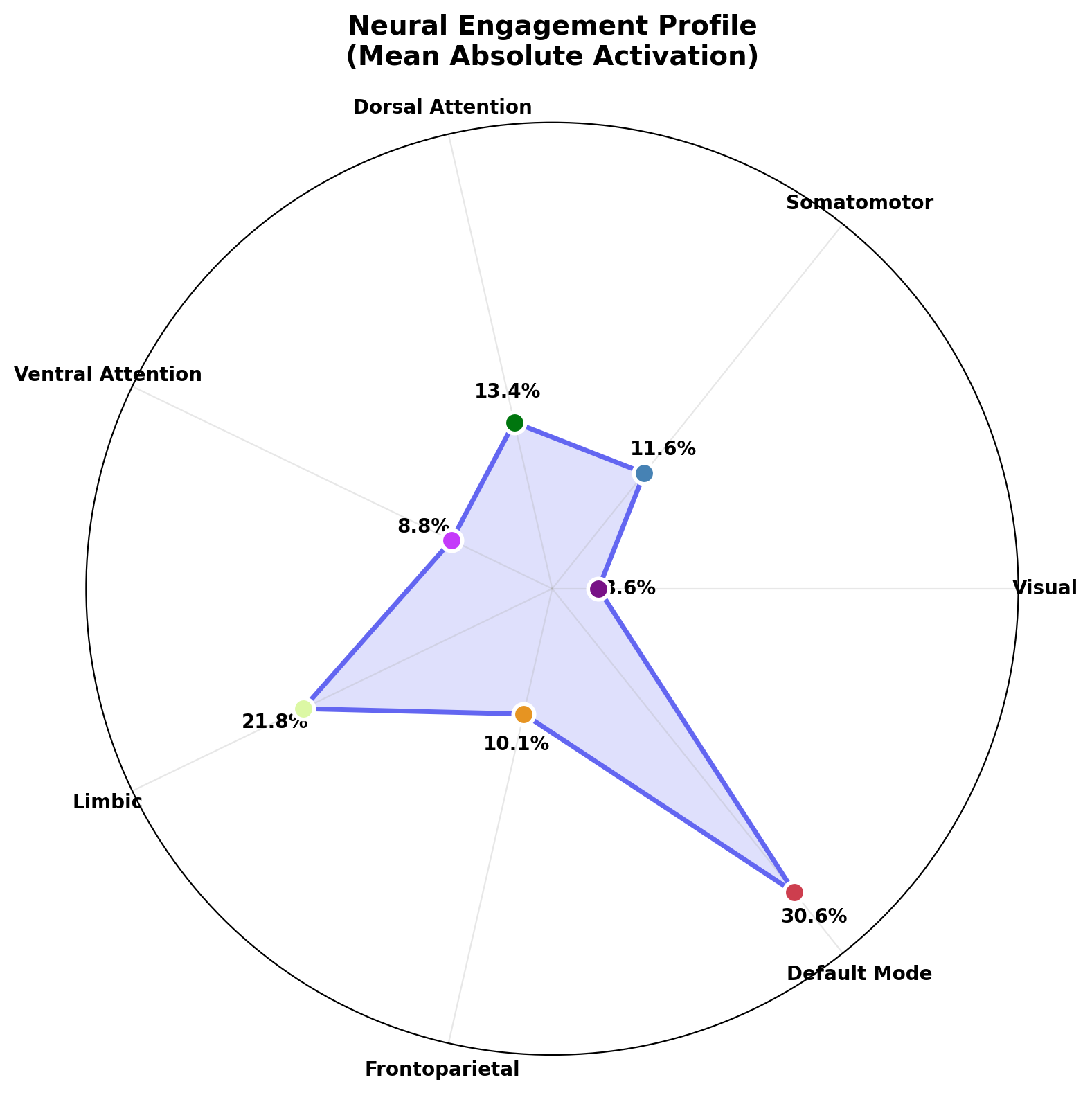
What each signal predicts, and what it misses
Neural captures aggregate attention and salience. It misses novelty out of distribution, and it is blind to cultural load.
Linguistic captures arousal and persuasion density. Berger and Milkman[4] showed high-arousal emotions (awe, anger, anxiety) drive sharing more than low-arousal ones. The signal is real. It misses narrative fit and audience context.
Cultural captures timing and resonance. It misses execution quality. Something on-trend and poorly made still flops.
Historical captures execution quality via pattern matching. It fails on genuinely novel creative, where no near-neighbors exist in the corpus.
Why fusion beats ensembling
Baltrusaitis, Ahuja, and Morency's 2018 TPAMI review[5] is the standard reference on multimodal fusion. Three strategies: early fusion (concatenate features), late fusion (combine scores), hybrid fusion (cross-attention between modalities during training). Late fusion is what most vendors do when they talk about combining signals. It is cheap and it loses cross-family interaction. Hybrid fusion is harder, requires joint training, and is where the applied lift actually lives.
The industry precedent is clear. CLIP[6] fused text and image. Flamingo[7] fused vision and language across shots. ImageBind[8] fused six modalities including audio and depth. Every system that reached frontier performance got there through joint representation learning, not through score averaging.
The evidence base
The ceiling of single-signal prediction is established in the literature. Cheng et al.[9] reached roughly 80 percent AUC predicting cascade doubling in social media using temporal and structural features alone. Reagan et al.[2] identified six basic emotional arcs across 1,327 works of fiction. Salganik, Dodds, and Watts's Music Lab experiment[10] showed that cultural success is highly path-dependent, a finding Martin et al.[11] extended to predictive limits in complex social systems.
Knutson, Falk, and the neuroforecasting tradition (see what is neuroforecasting) established that small-sample neural data predicts aggregate behavior at r of 0.3 to 0.8 depending on stimulus type and outcome. Persado and Phrasee case studies[12] report 25 to 40 percent engagement lifts from AI-optimized emotional copy, with Persado's JPMorgan Chase deployment claiming a 450 percent CTR lift on select campaigns.
None of this is magic. Each number is a moderate effect in its lane. The argument for fusion is that moderate effects in four lanes, properly combined, clear ceilings that single lanes never will.
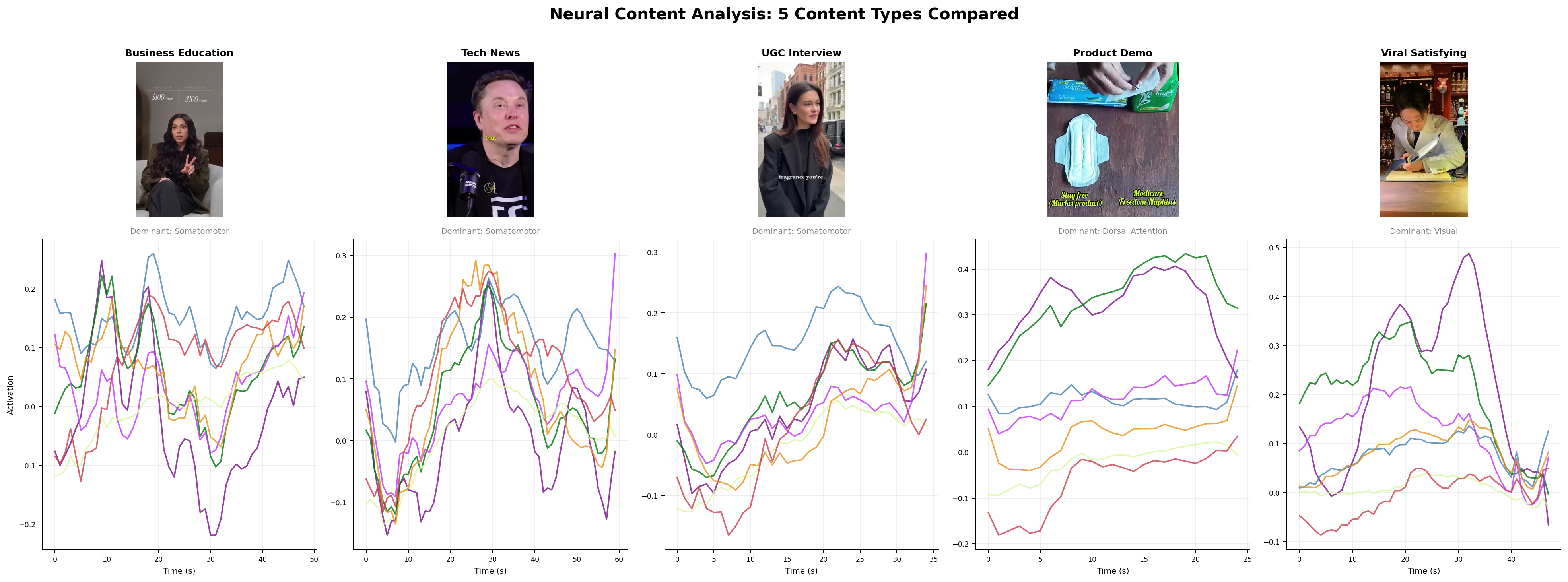
A working rubric
A simple composite score that an operator can run before shipping:
- Neural attention (0 to 100). Predicted cortical response, aggregated across subject population. Threshold: above the 50th percentile for the format.
- Linguistic affect (0 to 100). Arousal-weighted valence plus persuasion density plus arc coherence. Threshold: above a minimum for the vertical.
- Cultural relevance (0 to 100). Distance to the top-50 active conversation topics in the target audience. Threshold: meaningful proximity on at least one axis without obvious imitation.
- Historical match (0 to 100). Best-10 nearest neighbors in the ad library and their 30-day performance distribution. Threshold: the median of similar creative should not be in the bottom quartile.
The composite is a weighted average. Weights depend on the category. Direct response paid social leans historical and linguistic. Brand film leans neural and cultural. No fixed recipe generalizes. That is why it has to be a fused model, not a scorecard.
Failure modes and anti-patterns
Score inflation. Teams optimize to the score, not the outcome. The score stops predicting. Sometimes called Goodhart's law.
Training-data contamination. The scoring model was trained on outcomes that include the exact creative being scored. Accuracy looks great and generalizes to nothing.
Hyper-accuracy distortion. Correlations above 0.9 on aggregate behavior should make the reader suspicious. Real moderate effects are r of 0.5 to 0.7 with wide confidence intervals[13].
False precision on novel stimuli. Watts's Everything Is Obvious[14] is the canonical warning. Post-hoc explanations of viral success describe paths that could have gone differently with a lucky change in the first hundred adopters.
What this framework implies for tooling
Predictive content scoring is infrastructure, not a single-vendor product. The sensible way to think about it is the same way serious teams think about their data platform: a stack of components that each do one thing well, with a shared evaluation and calibration layer on top. OpenAffect sits on that layer and is built around the four signal families (see the manifesto).
The test of any scoring system is calibration against real-world outcomes. We publish ours (see the calibration page) because that is the only way the category gets honest.
References
- 1Meta AI. TRIBE v2: A brain predictive foundation model. 2026.
- 2Reagan, Mitchell, Kiley, Danforth, Dodds. Emotional arcs of stories. EPJ Data Science 2016.
- 3Pennebaker et al. Linguistic Inquiry and Word Count (LIWC).
- 4Berger and Milkman. What Makes Online Content Viral? JMR 2012.
- 5Baltrusaitis, Ahuja, Morency. Multimodal machine learning survey. TPAMI 2018.
- 6Radford et al. CLIP. 2021.
- 7Alayrac et al. Flamingo. 2022.
- 8Girdhar et al. ImageBind. 2023.
- 9Cheng, Adamic, Dow, Kleinberg, Leskovec. Can cascades be predicted? WWW 2014.
- 10Salganik, Dodds, Watts. Experimental study of inequality and unpredictability. Science 2006.
- 11Martin, Hofman, Sharma, Anderson, Watts. Exploring limits to prediction. WWW 2016.
- 12Persado and Phrasee case studies.
- 13Venkatraman et al. Predicting advertising success beyond traditional measures. JMR 2015.
- 14Watts. Everything Is Obvious. Crown 2011.